This statistical prediction tool is particularly useful for the target variable (predictand) in regions of high spatial-temporal variability. It is applied to the Jun-Sep (JJAS) seasonal precipitation in western Ethiopia, but the techniques can be generally applied to other hydroclimatic variables of interest.
Study Region
Large interannual variability and highly variable spatial patterns of JJAS seasonal precipitation add complexity to attribution and prediction. Teleconnected large-scale climate variables are shown to be influential, particularly El Niño–Southern Oscillation (ENSO) – warmer (colder) equatorial Pacific SST (from El Niño/La Niña) typically brings deficit (excess) JJAS seasonal total precipitation to the study region; however, the extent of influence varies from location to location.
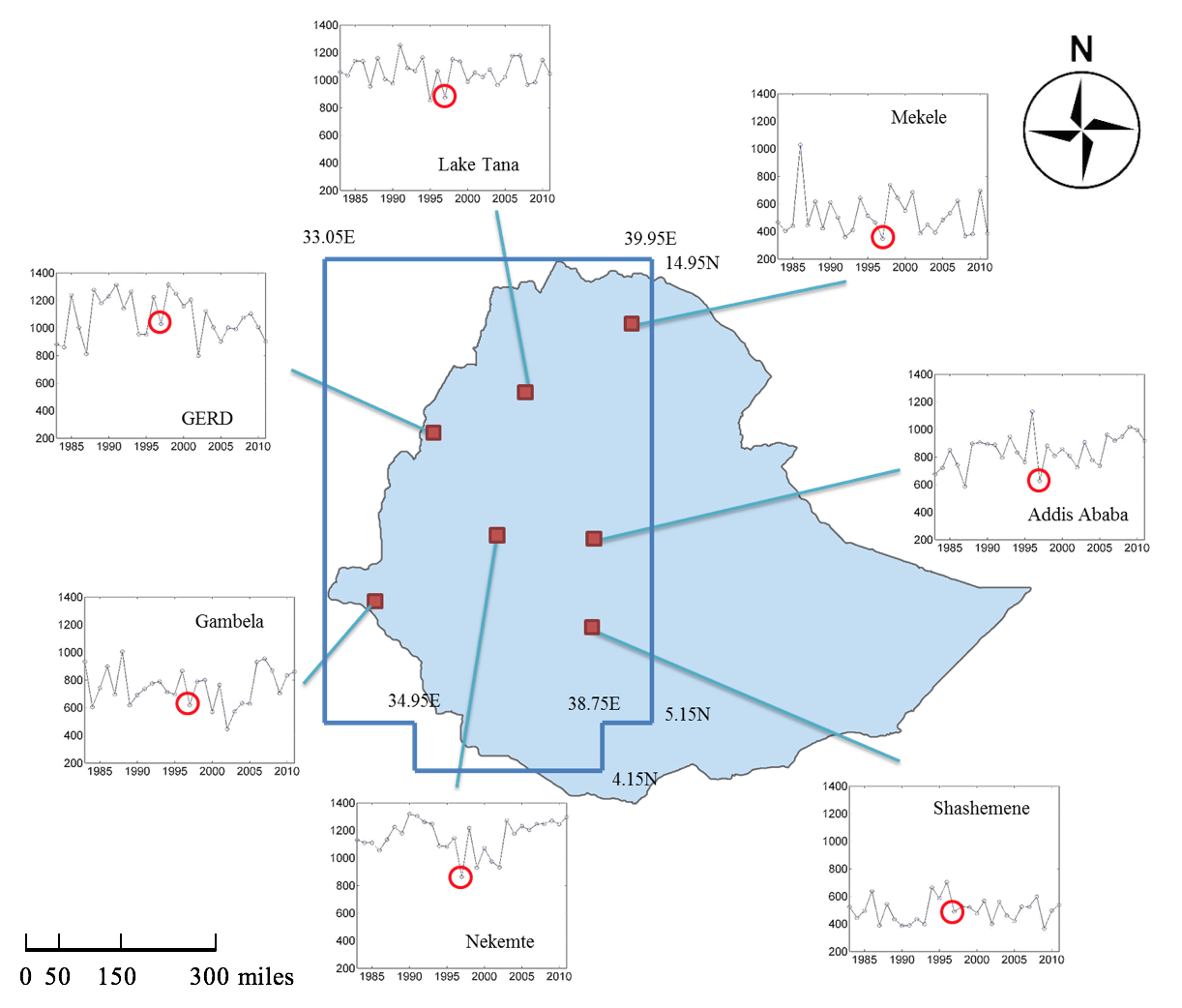
Figure 1: Study region (framed) of Western Ethiopia and sample sites with June-September seasonal total precipitation (mm) time-series from 1983 to 2011. Circles indicate the precipitation in 1997 which is a strong El Niño year.
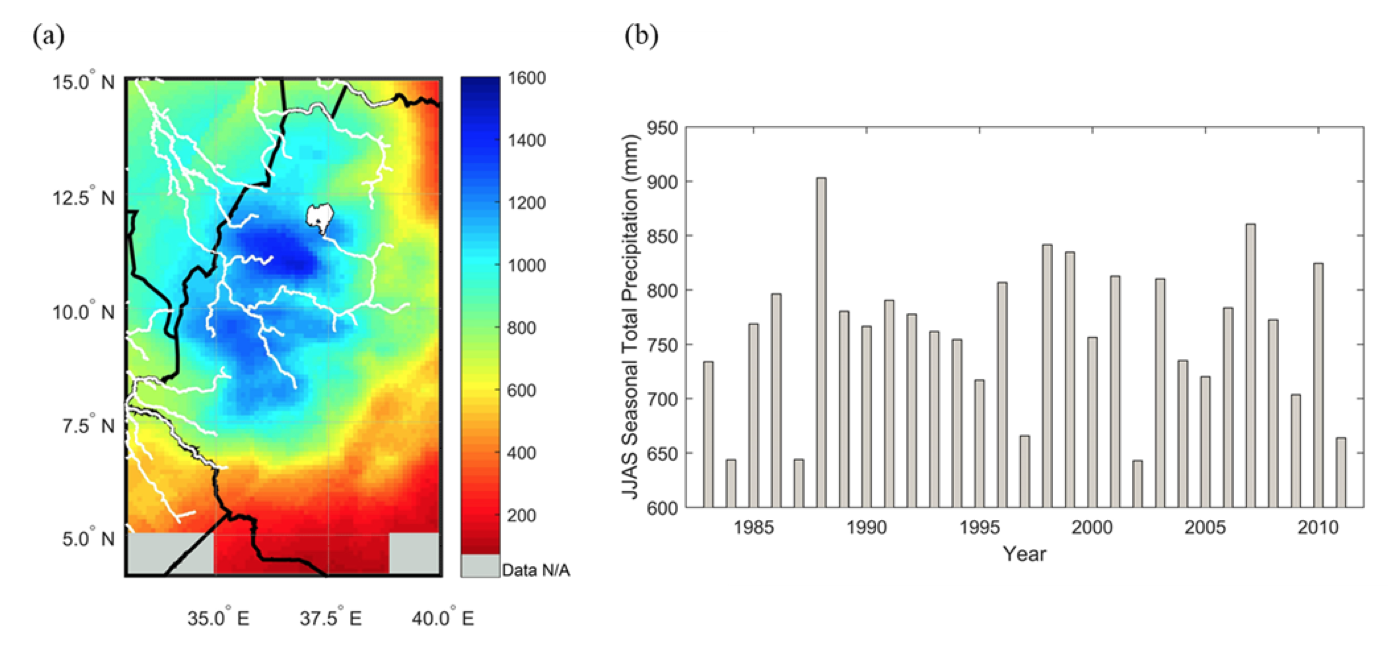
Figure 2: Spatial and temporal variability of June-September seasonal total precipitation in western Ethiopia: (a) spatial pattern of temporal-average, and (b) spatial-average time series.
Objective Cluster Analysis
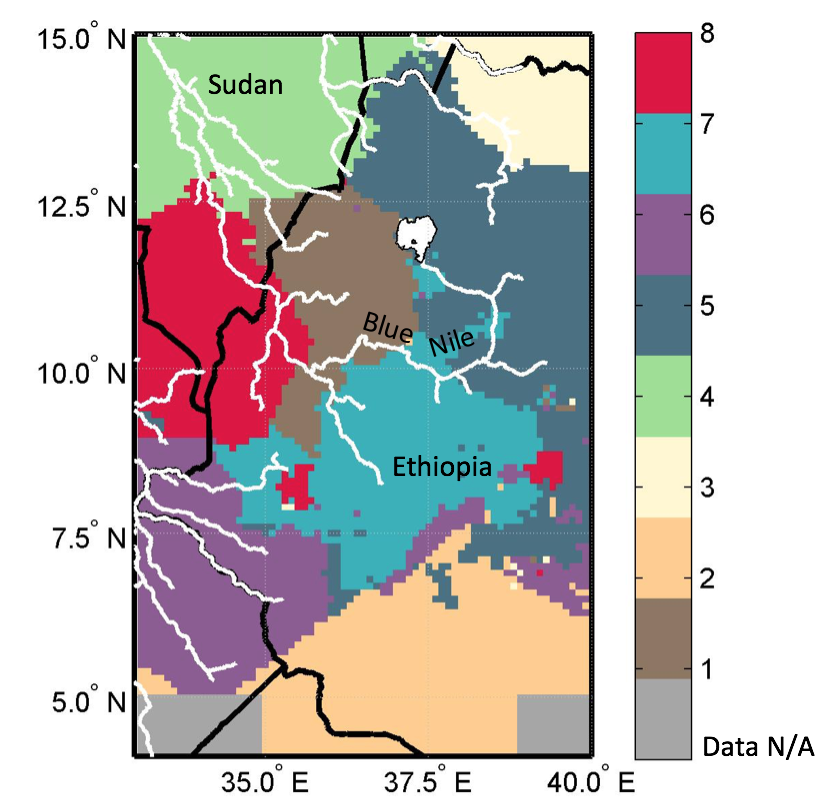
Hierarchical and nonhierarchical (k-means) clustering techniques on a gridded dataset of JJAS seasonal precipitation for objective and automatic delineation are evaluated. For this application, k-means clustering method is found to be superior primarily because it produces much more stable cluster boundaries. The 8 homogeneous regions based on k-means cluster analysis are therefore used for subsequent prediction. Additional information on comparison of clustering techniques and objective selection of the number of cluster can be found in Zhang et al. (2016).
Figure 3: Regionalization map of 8 homogeneous regions based on k-means cluster analysis, marked by different colors, and with country boundary and river profile.
Potential Predictors Selection
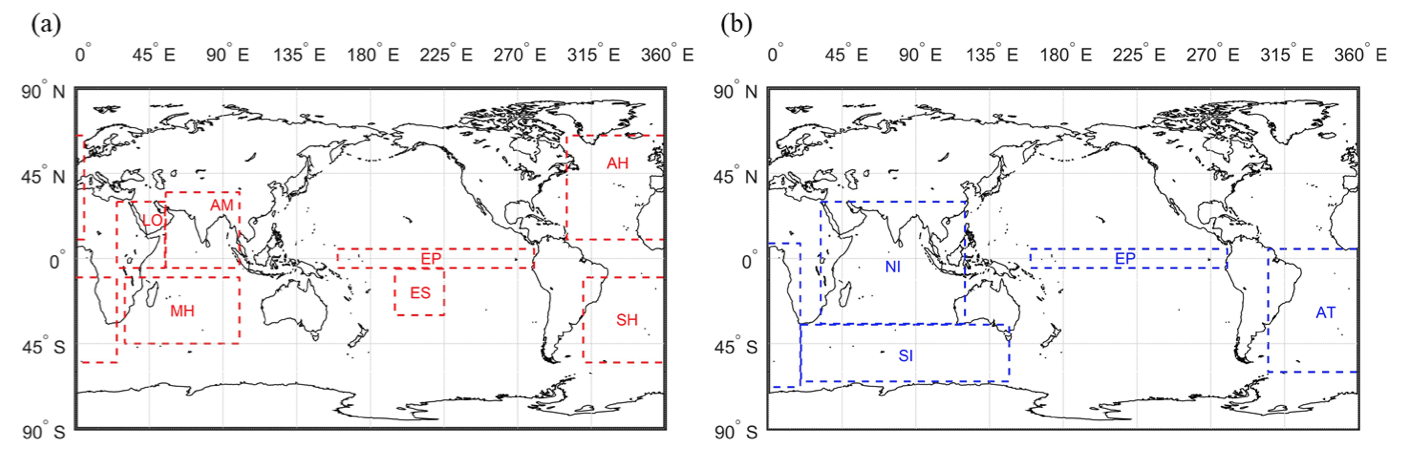
Season-ahead (March-May) or month-ahead (May) large-scale climate variables, including sea surface temperature (SST), sea level pressure (SLP), geopotential height (GH) at 500mb, and surface air temperature (SAT), in physically relevant and justifiable regions are evaluated and selected as potential predictors.
Figure 4: Justifiable climate regions globally for selecting predictors: (a) For SLP and GH at 500 mb with regions including EP, ES, LO, AH, SH, MH, and AM. For SAT, only LO is included. (b) For SST with regions including EP, NI, SI, and AT. Note: EP – equatorial Pacific region, ES – Tahiti island for ENSO measurement, LO – local region, AH – Azores High, SH – St Helena High, MH – Mascarene High, AM – SW Asian Monsoon, NI – North Indian Ocean, SI – South Indian Ocean, AT – Equatorial/South Atlantic Ocean.
Statistical Prediction Model
The top principal components of those potential predictors are used as predictors – the direct inputs into a multiple linear regression model. A statistical prediction model is built for each homogeneous region, producing a cluster-level prediction, which is then regressed to local-level (grid-level) prediction. This is compared against prediction without cluster analysis and dynamical prediction model outputs. Additional information can be found in Zhang et al. (in review).
*To avoid overfitting, the entire process including predictor selection and statistical modeling is processed using cross-validation.
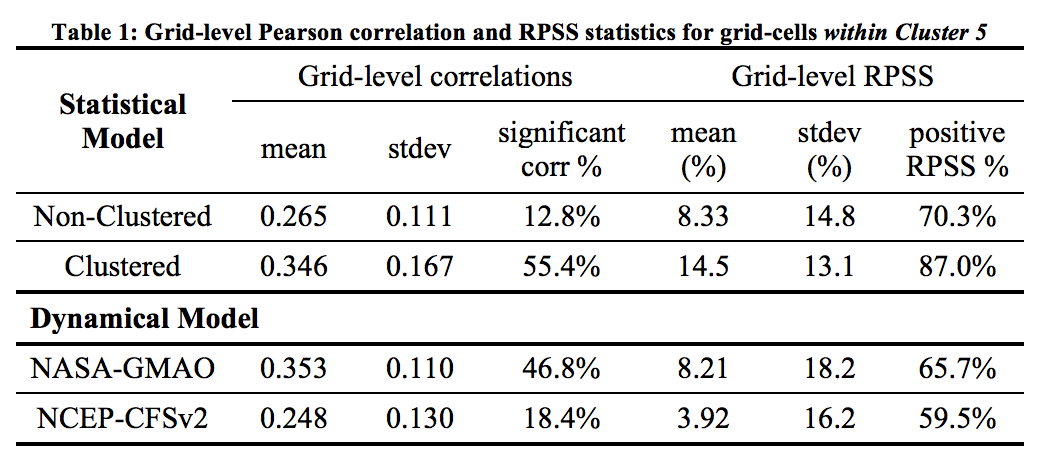
Selected Prediction Results
The results show promises in the statistical model with cluster analysis as a precursor for some regions, compared to non-clustered statistical predictions and dynamical model predictions. Relatively poor prediction performance is evident in some locations such as southwestern Ethiopia, where the hydroclimatic processes that produce precipitation might be driven by local factors or other regional climate patterns rather than large-scale climate variables identified in this study. Discussions on predictions skills in different regions in connection to climatic mechanisms such as ENSO, Indian Ocean Monsoon, moisture transport affecting different parts of the study regions can be found in Zhang et al. (in review).
References:
ZHANG, Y., MOGES, S. & BLOCK, P. 2016. Optimal Cluster Analysis for Objective Regionalization of Seasonal Precipitation in Regions of High Spatial-Temporal Variability: Application to Western Ethiopia. Journal of Climate, 29, 3697-3717.
ZHANG, Y., MOGES, S. & BLOCK, P. in review. Does objective cluster analysis serve as a useful precursor to seasonal precipitation prediction at local scale? Application to western Ethiopia.